
A software engineer at LinkedIn has written a monster of a blog post about “The Log”, a building block for large-scale data systems. The concepts in this post are near and dear to my heart due to my work on precisely these kinds of problems at Parse.ly.
What is “a log”?
The log is similar to the list of all credits and debits and bank processes; a table is all the current account balances. If you have a log of changes, you can apply these changes in order to create the table capturing the current state. This table will record the latest state for each key (as of a particular log time). There is a sense in which the log is the more fundamental data structure: in addition to creating the original table you can also transform it to create all kinds of derived tables.
At Parse.ly, we just adopted Kafka widely in our backend to address just these use cases for data integration and real-time/historical analysis for the large-scale web analytics use case. Prior, we were using ZeroMQ, which is good, but Kafka is better for this use case.
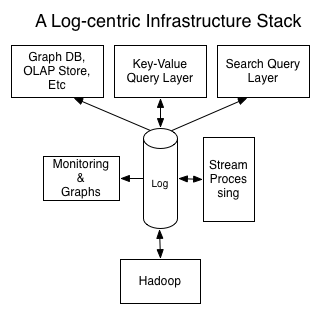
We have always had a log-centric infrastructure, not born out of any understanding of theory, but simply of requirements. We knew that as a data analysis company, we needed to keep data as raw as possible in order to do derived analysis, and we knew that we needed to harden our data collection services and make it easy to prototype data aggregates atop them.
I also recently read Nathan Marz’s book (creator of Apache Storm), which proposes a similar “log-centric” architecture, though Marz calls it a “master dataset” and uses the fanciful term, “Lambda Architecture”. In his case, he describes that atop a “timestamped set of facts” (essentially, a log) you can build any historical / real-time aggregates of your data via dedicated “batch” and “speed” layers. There is a lot of overlap of thinking in that book and in this article.
Continue reading The Log: a building block for large-scale data systems